
|
|
|
|
|
|
|
|
|
|
|
|
|
|
 |
 |
|
|
|
|
|
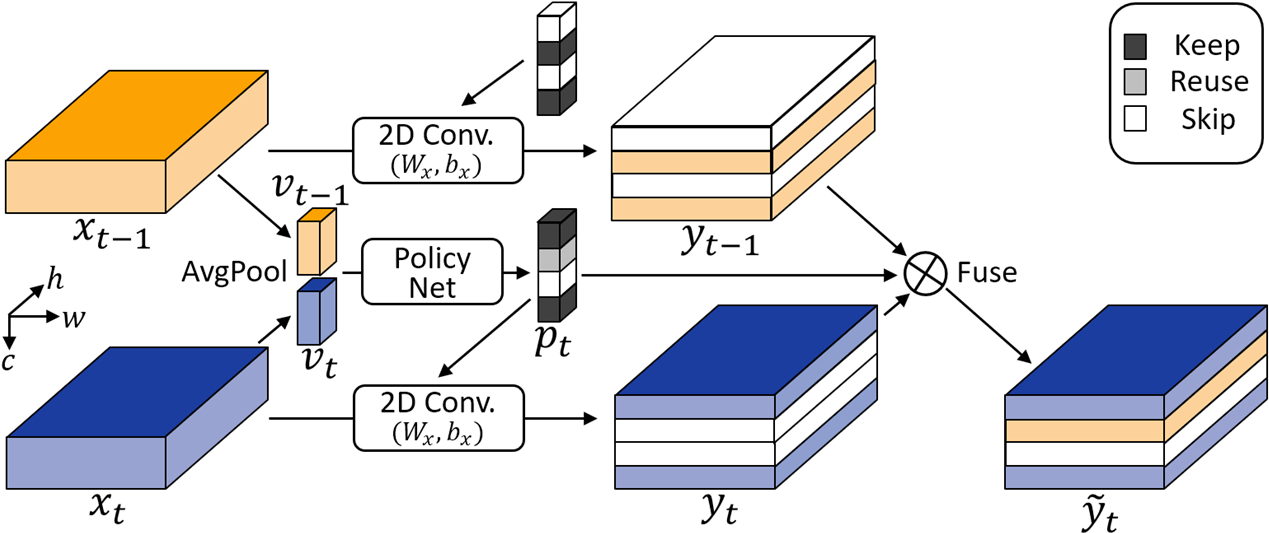
Yue Meng, Rameswar Panda, Chung-Ching Lin, Prasanna Sattigeri, Leonid Karlinsky, Kate Saenko, Aude Oliva, and Rogerio Feris. AdaFuse: Adaptive Temporal Fusion Network for Efficient Action Recognition International Conference on Learning Representations (ICLR), 2021 [PDF][Code] |